Em estoque no nosso parceiro, no entanto, os prazos de entrega podem ser de cerca de 8 a 12 semanas, independentemente, devido ao arquivamento da certificação EUS sobre os requisitos de exportação. Disponibilidade, preços e alocações podem flutuar diariamente. Todas as vendas são finais. Sem devoluções ou cancelamentos.
BLOCO DE CONSTRUÇÃO ESSENCIAL DO CENTRO DE DADOS DE IA
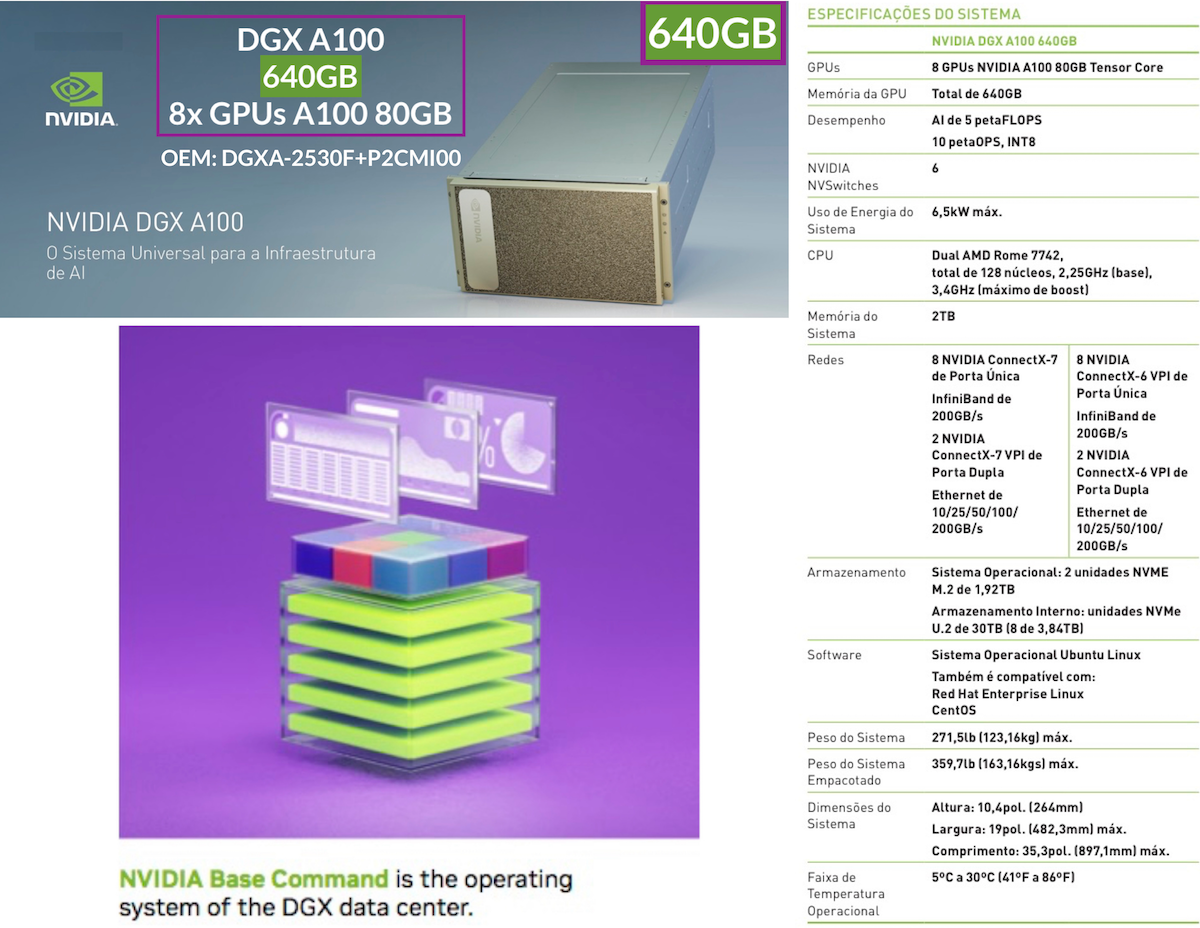
NVIDIA DGX™ A100 é o sistema universal para todas as cargas de trabalho de IA, oferecendo densidade de computação, desempenho e flexibilidade sem precedentes em um sistema de IA de 5 petaFLOPS.
O NVIDIA DGX A100 apresenta o acelerador mais avançado do mundo, a GPU NVIDIA A100 Tensor Core, permitindo que as empresas consolidem treinamento, inferência e análise em uma infraestrutura de IA unificada e fácil de implementar que inclui acesso direto aos especialistas em IA da NVIDIA.
O desafio de dimensionar a IA empresarial
Toda empresa precisa se transformar usando inteligência artificial (IA), não apenas para sobreviver, mas para prosperar em tempos desafiadores.
No entanto, a empresa requer uma plataforma para infraestrutura de IA que melhore as abordagens tradicionais, que historicamente envolviam arquiteturas de computação lentas que eram isoladas por cargas de trabalho de análise, treinamento e inferência.
A abordagem antiga criava complexidade, aumentava os custos, restringia a velocidade de escala e não estava pronta para a IA moderna.
Empresas, desenvolvedores, cientistas de dados e pesquisadores precisam de uma nova plataforma que unifique todas as cargas de trabalho de IA, simplificando a infraestrutura e acelerando o ROI.
O sistema universal para cada carga de trabalho de IA
O DGX A100 define um novo padrão para densidade de computação, empacotando 5 petaFLOPS de desempenho de IA em um fator de forma 6U, substituindo a infraestrutura de computação legada por um único sistema unificado.
O DGX A100 também oferece a capacidade sem precedentes de fornecer alocação refinada de poder de computação, usando o recurso de GPU multi-instância na GPU NVIDIA A100 Tensor Core, que permite aos administradores atribuir recursos que são do tamanho certo para cargas de trabalho específicas.
Isso garante que os trabalhos maiores e mais complexos sejam suportados, juntamente com os mais simples e menores.
Executando a pilha de software DGX com software otimizado da NGC, a combinação de poder de computação denso e flexibilidade completa de carga de trabalho tornam o DGX A100 uma escolha ideal para implantações de nó único e clusters Slurm e Kubernetes em larga escala implantados com NVIDIA DeepOps.
Definindo a inovação em IA com NVIDIA DGX A100
Organizações de todos os tipos estão incorporando IA em seus processos de pesquisa, desenvolvimento, produtos e negócios.
Isso as ajuda a atingir e superar suas metas específicas e também as ajuda a ganhar experiência e conhecimento para enfrentar desafios ainda maiores.
No entanto, as infraestruturas de computação tradicionais não são adequadas para IA devido às arquiteturas lentas de CPU e aos requisitos de sistema variáveis para diferentes cargas de trabalho e fases do projeto.
Isso aumenta a complexidade, aumenta o custo e limita a escala.
Para ajudar as organizações a superar esses desafios e ter sucesso em um mundo que precisa desesperadamente do poder da IA para resolver grandes desafios, a NVIDIA projetou a primeira família de sistemas do mundo desenvolvida especificamente para IA — os sistemas NVIDIA DGX. Ao aproveitar as poderosas GPUs NVIDIA e o software de IA otimizado da NVIDIA NGC, os sistemas DGX oferecem desempenho sem precedentes e eliminam a complexidade da integração.
Agora, a NVIDIA apresentou o NVIDIA DGX A100. Construído na nova GPU NVIDIA A100 Tensor Core, o DGX A100 é a terceira geração de sistemas DGX e é o sistema universal para infraestrutura de IA.
Apresentando cinco petaFLOPS de desempenho de IA, o DGX A100 se destaca em todas as cargas de trabalho de IA: análise, treinamento e inferência.
Ele permite que as organizações padronizem em um único sistema que pode acelerar qualquer tipo de tarefa de IA a qualquer momento e se ajustar dinamicamente às necessidades de computação em mudança ao longo do tempo.
Essa flexibilidade incomparável reduz custos, aumenta a escalabilidade e torna o DGX A100 o bloco de construção fundamental do moderno data center de IA.
Arquitetura do sistema
GPU NVIDIA A100: GPU de data center de oitava geração para a era da computação elástica
GPU NVIDIA A100: GPU de data center de oitava geração para a era da computação elástica
No núcleo, o sistema NVIDIA DGX A100 aproveita a GPU NVIDIA A100, projetada para acelerar com eficiência grandes cargas de trabalho complexas de IA, bem como várias cargas de trabalho pequenas, incluindo aprimoramentos e novos recursos para maior desempenho em relação à GPU V100.
A GPU A100 incorpora 40 GB de memória HBM2 de alta largura de banda, caches maiores e mais rápidos e foi projetada para reduzir a complexidade de software e programação de IA e HPC.
A GPU NVIDIA A100 inclui os seguintes novos recursos para acelerar ainda mais a carga de trabalho de IA e o desempenho do aplicativo HPC:
Núcleos Tensor de terceira geração
Aceleração de esparsidade
GPU multi-instância
Núcleos Tensor de terceira geração
A GPU NVIDIA A100 inclui novos Núcleos Tensor de terceira geração. Os Tensor Cores são núcleos de computação especializados e de alto desempenho que realizam cálculos de multiplicação e acumulação de matrizes (MMA) de precisão mista em uma única operação, fornecendo desempenho acelerado para cargas de trabalho de IA e aplicativos HPC.
Os Tensor Cores de primeira geração usados no NVIDIA DGX-1 com V100 forneceram desempenho acelerado com MMA de precisão mista em FP16 e FP32.
Esta última geração no DGX A100 usa tamanhos de matriz maiores, melhorando a eficiência e fornecendo o dobro do desempenho dos Tensor Cores V100, juntamente com desempenho aprimorado para tipos de dados INT4 e binários. A GPU A100 Tensor Core também adiciona os seguintes novos tipos de dados:
TF32
IEEE Compliant FP64
BF16 (as operações Tensor Core de precisão mista BF16/FP32 são executadas na mesma velocidade que as operações Tensor Core de precisão mista FP16/FP32, fornecendo outra opção para treinamento de aprendizado profundo)
Structured sparsity
A esparsidade é uma abordagem relativamente nova para redes neurais e promete aumentar a capacidade de modelos de redes neurais profundas reduzindo o número de conexões necessárias em uma rede e conservando recursos.
Com a GPU NVIDIA A100, a NVIDIA se posiciona na vanguarda desse esforço incorporando a esparsidade estruturada.
Com a esparsidade estruturada, cada nó em uma rede esparsa executa a mesma quantidade de buscas e cálculos de dados e resulta em distribuição de carga de trabalho equilibrada e melhor utilização de nós de computação.
Além disso, a esparsidade é usada para executar a compactação de matriz, o que fornece benefícios como duplicar operações de multiplicação-acumulação.
O resultado é uma computação acelerada do Tensor Core em uma variedade de redes de IA e maior rendimento do treinamento FP, bem como treinamento de inferência.
O INT8 no A100 oferece 20X mais desempenho do que o INT8 no V100.
As operações do TF32 Tensor Core no A100 oferecem 20X mais desempenho do que as operações FP32 FFMA padrão no V100.
As operações do FP64 Tensor Core compatíveis com IEEE no A100 oferecem 2,5X mais desempenho do que as operações FP64 padrão no V100 para aplicativos HPC.
GPU multi-instância
A GPU NVIDIA A100 incorpora o novo recurso GPU multi-instância (MIG). O MIG usa particionamento espacial para dividir os recursos físicos de uma única GPU A100 em até sete instâncias de GPU independentes.
Com o MIG, a GPU NVIDIA A100 pode fornecer qualidade de serviço garantida com rendimento até 7x maior do que o V100 com instâncias simultâneas por GPU.
Em uma GPU NVIDIA A100 com MIG habilitado, cargas de trabalho de computação paralelas podem acessar memória de GPU isolada e recursos de GPU física, pois cada instância de GPU tem sua própria memória, cache e multiprocessador de streaming.
Isso permite que vários usuários compartilhem a mesma GPU e executem todas as instâncias simultaneamente, maximizando a eficiência da GPU.
O MIG pode ser habilitado seletivamente em qualquer número de GPUs no sistema DGX A100 — nem todas as GPUs precisam ser habilitadas para MIG.
No entanto, se todas as GPUs em um sistema DGX A100 forem habilitadas para MIG, até 56 usuários podem aproveitar simultaneamente e independentemente a aceleração da GPU.
Os casos de uso típicos que podem se beneficiar do MIG são os seguintes:
Vários trabalhos de inferência com tamanhos de lote de um que envolvem modelos pequenos e de baixa latência e que não exigem todo o desempenho de uma GPU completa
Notebooks Jupyter para exploração de modelos
Uso de recursos compartilhados e multiusuário de locatário único
Levando isso mais longe no DGX A100 com 8 GPUs A100, você pode configurar GPUs diferentes para cargas de trabalho muito diferentes, conforme mostrado no exemplo a seguir:
4 GPUs para treinamento de IA
2 GPUs para HPC ou análise de dados
2 GPUs no modo MIG, particionadas em instâncias de 14 MIG, cada uma executando inferência
NVLink e NVSwitch de terceira geração para acelerar grandes cargas de trabalho complexas
O sistema DGX A100 contém seis fabrics NVIDIA NVSwitch de segunda geração que interconectam as GPUs A100 usando interconexões de alta velocidade NVIDIA NVLink de terceira geração.
Cada GPU A100 usa doze interconexões NVLink para se comunicar com todos os seis nós NVSwitch, o que significa que há dois links de cada GPU para cada switch.
Isso fornece uma quantidade máxima de largura de banda para se comunicar entre GPUs pelos links.
O NVSwitch de segunda geração é duas vezes mais rápido do que a versão anterior, que foi introduzida pela primeira vez no sistema NVIDIA DGX-2.
A combinação de seis interconexões NVSwitch e NVLink de terceira geração permite que a comunicação individual de GPU para GPU atinja o pico de 600 GB/s, o que significa que se todas as GPUs estiverem se comunicando entre si, a quantidade total de dados transferidos atinge o pico de 4,8 TB/s para ambas as direções.
Maior rendimento de rede com Mellanox ConnectX-6
O dimensionamento multissistema de aprendizado profundo de IA e cargas de trabalho computacionais de HPC requer comunicações fortes entre GPUs em vários sistemas para corresponder ao desempenho significativo de GPU de cada sistema.
Além do NVLink para comunicação de alta velocidade internamente entre GPUs, o servidor DGX A100 é configurado com oito portas Mellanox ConnectX-7 200 Gb/s HDR InfiniBand de porta única (também configuráveis como portas Ethernet de 200 Gb/s) que podem ser usadas para construir um cluster de alta velocidade de sistemas DGX A100.
Os métodos mais comuns de mover dados de e para a GPU envolvem aproveitar o armazenamento integrado e usar os adaptadores de rede Mellanox ConnectX-7 por meio de acesso direto à memória remota (RDMA). O DGX A100 incorpora um relacionamento um para um entre as placas de E/S e as GPUs, o que significa que cada GPU pode se comunicar diretamente com fontes externas sem bloquear o acesso de outra GPU à rede.
As placas de E/S Mellanox ConnectX-7 oferecem conectividade flexível, pois podem ser configuradas como HDR Infiniband ou Ethernet de 200 Gb/s.
Isso permite que o NVIDIA DGX A100 seja agrupado com outros nós para executar cargas de trabalho de HPC e IA usando baixa latência, alta largura de banda InfiniBand ou RDMA sobre Ethernet convergente (RoCE).
A GPU DGX A100 inclui uma placa ConnectX-6 de porta dupla adicional que pode ser usada para conexão de alta velocidade com armazenamento externo. A flexibilidade na configuração de E/S também permite conectividade com uma variedade de opções de armazenamento em rede de alta velocidade.
Se você está buscando por hardware para:
High Performance Computing
Climate and Weather Modeling
Industrial, Logistic & Retail Automation
Visão Computacional
Conversational AI
Deep Learning
Drug Discovery
UAVs
Finance & Economics
UGVs
AI / Deep Learning Training
NetWork
Healthcare Business
Cloud & IA Data Center
Intelligence & Analytics
Rugged Notebooks
A Loja do Jangão é o lugar certo para você.
Por que escolher a Loja do Jangão?
Produtos de Qualidade Ouro: A loja trabalha apenas com marcas renomadas e produtos com garantia de qualidade.
Amplo catálogo: Encontre tudo o que você precisa em um só lugar, desde equipamentos para indústria, logística & retail, pesquisadores, professores, estudantes, entusiastas, agro, governo, exército, etc.
Atendimento especializado: Especialistas que irão apontar o produto ideal para sua necessidade.
Formas de pagamento facilitadas: A loja oferece diversas opções de pagamento, incluindo cartão de crédito com parcelamento em até 10x sem juros, boleto bancário, PIX, FINAME, e outros que dependem de bancos.
Entrega rápida e segura: Seus produtos são entregues com rapidez e segurança para todo o Brasil. Importamos do mundo inteiro. Temos experiência de +30 anos em comércio exterior.
É um prazer compartilhar com você nosso portfólio:
A Loja do Jangão é uma excelente opção para quem busca produtos de alta especificação e atendimento apontado para os últimos lançamentos das fábricas.
Observação: Para uma análise mais detalhada e personalizada, seria interessante conhecer um pouco mais sobre suas necessidades e preferências. Podemos até lhe ajudar em projetos com seus clientes.
E é com satisfação que nos colocamos à sua inteira disposição para futuras necessidades de orçamentos de produtos importados,mesmo que não estejam no nosso catálogo / website.
Já somos fornecedores de empresas do setor automobilístico, IA , Indústrias, Fundações, Universidades e Empresas dos Setores de Inteligência Artificial / Engenharia Ambiental / Energia , Consórcios de Vias, etc.